0x01 问题描述
最近在写一个批量扫描工具,使用多线程爬取目标然后将数据存入数据库中,但是在使用sqlalchemy 引擎时线程数过多就会出现错误:“Too many connections”

0x02 解决方案
增加数据库最大连接(不可取)
查了一下数据库最大连接数,当超过最大连接数数据库就会报出去错误,所以适当改大可以勉强解决问题。
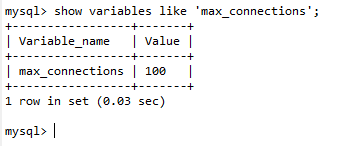
不使用连接池
sqlalchemy在
create_engine时有很多可选参数,比如:1
2
3
4
5engine = create_engine('mysql://user:password@localhost:3306/test?charset=utf8mb4',
echo=False, # 打印info
pool_size=100, # 连接池大小 默认为5
pool_recycle=3600, # 连接回收时间
)默认不指定连接池设置的话 ,SQLAlchemy会使用一个 QueuePool 绑定在新创建的引擎上,并附上合适的连接池参数。并发连接超过超过最大连接数,就会产生“Too many connections”错误,所以参考sqlalchemy文档完全可以不使用连接池即可解决问题。
一个栗子:
1
2from sqlalchemy.pool import NullPool
engine = create_engine("mysql://root:pass@hostname/dbname", poolclass=NullPool)